In most cases, upgrading an existing instance of SHRINE is a relatively quick process. Exceptions to this rule include older versions of SHRINE that contained substantial changes to configuration files and other portions of the file structure. The instructions here specifically describe an upgrade path from SHRINE 1.25.4 to SHRINE 2.0.0.
Warning
SHRINE 2.0.0 is not backwards-compatible with any previous version!
This guide makes the following assumptions of a current 1.25.4 system. Make sure all of these conditions are satisfied before proceeding:
- i2b2 1.7.09c is installed and operational.
- SHRINE 1.25.4 is installed and operational.
- The SHRINE Data Steward has been installed and configured properly.
- The SHRINE Dashboard has been installed and configured properly.
Shut Down SHRINE
Before starting the upgrade process, make sure SHRINE's Tomcat is not running. Leaving it running during this process can cause problems, especially with unpacking new .war files. Simply run the following command:
$ /opt/shrine/tomcat/bin/shutdown.sh
Backup your current SHRINE configuration
Now that SHRINE is stopped, it is a good idea to back up the current versions of the components we will be upgrading. The exact method for making this backups may vary, but these instructions will place the backups in a folder called /opt/shrine/upgrade-backups.
Start by creating a folder to contain these backups:
$ mkdir /opt/shrine/upgrade-backups
Make especially sure that the shrine-webclient/ folder is backed up. If you choose not to make any backups, make sure to at least keep a copy of i2b2_config_data.js and js-i2b2/cells/SHRINE/cell_config_data.js!
$ mv /opt/shrine/tomcat/webapps/shrine-webclient /opt/shrine/upgrade-backups/shrine-webclient
Make especially sure that the shrine.keystore is backed up. If you lose the private side of a cert you may not be able to recover it.
$ cp /opt/shrine/shrine.keystore /opt/shrine/upgrade-backups/shrine.keystore
Remove old SHRINE components
SHRINE will use new components, so to avoid conflicts with older files, you can remove the old .war files with this command:
$ rm /opt/shrine/tomcat/webapps/*.war
Also, you can remove all the existing folders from the /webapps directory:
$ rm -rf /opt/shrine/tomcat/webapps/shrine/ $ rm -rf /opt/shrine/tomcat/webapps/shrine-proxy/ $ rm -rf /opt/shrine/tomcat/webapps/shrine-metadata/ $ rm -rf /opt/shrine/tomcat/webapps/shrine-dashboard/ $ rm -rf /opt/shrine/tomcat/webapps/steward/
Deploy New .war Files
Deploy New SHRINE Core
Next, we will retrieve the new SHRINE war files from the HMS Sonatype Nexus server at: https://repo.open.med.harvard.edu/nexus/content/groups/public/net/shrine/shrine-war/2.0.0/. From there, download shrine-war-2.0.0.war to the webapps/ directory on the SHRINE server and rename it to shrine.war.
For example:
$ cd /opt/shrine/tomcat/webapps $ wget https://repo.open.med.harvard.edu/nexus/content/groups/public/net/shrine/shrine-war/2.0.0/shrine-war-2.0.0.war -O shrine.war
Deploy New SHRINE API Service
Like other SHRINE artifacts, the SHRINE API Service can be found on the HMS Sonatype Nexus server at https://repo.open.med.harvard.edu/nexus/content/groups/public/net/shrine/shrine-api-war/2.0.0/. From there, download shrine-api-war-2.0.0.war to the webapps/ directory on the SHRINE server and rename it to shrine-api.war.
For example:
$ cd /opt/shrine/tomcat/webapps $ wget https://repo.open.med.harvard.edu/nexus/content/groups/public/net/shrine/shrine-api-war/2.0.0/shrine-api-war-2.0.0.war -O shrine-api.war
Changes to SHRINE's Configuration File - shrine.conf
Since SHRINE 1.25.4, there are a couple of changes to SHRINE's configuration file. If you want to, skip ahead to the sample shrine.conf section and copy the entire contents of the file for use (replacing with your own site specific values).
Part of the new data service allows a node to look up information about itself
Each node can ask the hub about itself and the hub. To ask about itself it needs a shared key with the hub. This will be a unique identifier, ie. "HarvardProdNode". Add that to shrine.conf:
shrine {
nodeKey = "UniqueFriendlyNodeName"
}
Remove the QEP user from the PM cell, and corresponding section from shrine.conf
Shrine now accesses the DSA's database directly from inside shrine-api.war. It no longer needs a special QEP user to authenticate to the Data Steward service. Delete that user from the PM cell, and remove this section from shrine.conf:
//shrine-steward config
shrineSteward {
qepUserName = "qep"
qepPassword = "changeit"
stewardBaseUrl = "https://shrine-node:6443"
}
Remove includeAggregateResults
Remove the formerly required "includeAggregateResults = false" from shrine.conf .
includeAggregateResults = false
Configure the webclient in shrine.conf
In SHRINE 2.0.0, you will need additional parameters to configure the behavior of the webclient. Please add this section in shrine.conf:
webclient {
domain = "i2b2demo"
name = "SHRINE"
siteAdminEmail = "email@example.com"
usernameLabel = "User Name"
passwordLabel = "User Password"
defaultNumberOfOntologyChildren = 10000 // the number of children to show when an ontology folder is expanded.
queryFlaggingInstructions = "Enter instructions for flagging queries here"
flaggingPlaceholderText = "Enter placeholder text for the query flagging text input field"
flaggingIconInstructions = "Enter text for when user mouses over the flagging information icon in the header of the Query History here"
}
The webclient has hard-coded default values for the userNameLabel, passwordLabel, and defaultNumberOfOntologyChildren fields if they are not configured; userNameLabel defaults to "SHRINE User", passwordLabel defaults to "SHRINE Password", and defaultNumberOfOntologyChildren defaults to 10000.
Remove Human-Readable node name property from shrine.conf
The nodeKey property is used by SHRINE internally instead, and the node structure (stored at the hub) holds a real human-readable name with a good assortment of punctuation and spaces, therefore, you will not need this line in shrine.conf anymore.
humanReadableNodeName = "Harvard Test Node"
Redirect webclient, steward, and dashboard to old URL links
Before you perform these steps, please make sure your Tomcat version is at least 8.5.x, but please do not install Tomcat version 9!
The URL to the SHRINE Webclient has changed from https://shrine_url:6443/shrine-webclient to https://shrine_url:6443/shrine-api/shrine-webclient.
The URL to the SHRINE Steward has changed from https://shrine_url:6443/steward to https://shrine_url:6443/shrine-api/shrine-steward.
The URL to the SHRINE Dashboard has changed from https://shrine_url:6443/shrine-dashboard to https://shrine_url:6443/shrine-api/shrine-dashboard.
To redirect the old URL and preserve existing bookmarks and history in browsers, specify a URL rewrite in Tomcat.
1. Add rewrite valve to conf/server.xml inside the Host configuration section
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true"><Valve className="org.apache.catalina.valves.rewrite.RewriteValve" />
2. Create a file name rewrite.config in conf/Catalina/localhost with the following contents
RewriteRule ^/shrine-webclient/* /shrine-api/shrine-webclientRewriteRule ^/steward/* /shrine-api/shrine-stewardRewriteRule ^/shrine-dashboard/* /shrine-api/shrine-dashboard
No need to specify a slick driver anymore
Now the system can select the slick driver based on the shrineDatabaseType property in shrine.conf.
If the selected slick driver causes problems it is OK to use the old properties - which will override the one chosen via shrineDatabaseType.
Sample SHRINE configuration file (for a downstream node)
Here's a sample shrine.conf for a 2.0.0 downstream node (it might be helpful to copy the entire contents of this file and then replace with your own institution's specific values):
shrine.conf
shrineHubBaseUrl = "https://shrine_hub_url:6443" //The shrine hub's URL as observed from this tomcat server
i2b2BaseUrl = "http://localhost:9090" //The local i2b2's URL as observed from this tomcat server
i2b2Domain = "i2b2demo" //recommended to change this to a unique domain
i2b2ShrineProjectName = "SHRINE"
shrine {
nodeKey = "unique-node-name" //node key to get information from the hub about this node
shrineDatabaseType = "mysql" //can be oracle, mysql, sqlserver
messagequeue {
blockingq {
serverUrl = ${shrineHubBaseUrl}/shrine-api/mom //point this to the network hub
}
}
webclient {
domain = ${i2b2Domain}
name = ${i2b2ShrineProjectName}
siteAdminEmail = "email@example.com"
usernameLabel = "User Name"
passwordLabel = "User Password"
defaultNumberOfOntologyChildren = 10000 // the number of children to show when an ontology folder is expanded.
queryFlaggingInstructions = "Enter instructions for flagging queries here"
flaggingPlaceholderText = "Enter placeholder text for the query flagging text input field"
flaggingIconInstructions = "Enter text for when user mouses over the flagging information icon in the header of the Query History here"
}
pmEndpoint {
url = ${i2b2BaseUrl}/i2b2/services/PMService/getServices
}
ontEndpoint {
url = ${i2b2BaseUrl}/i2b2/services/OntologyService/
}
hiveCredentials {
domain = ${i2b2Domain}
username = "demo"
password = "demouser"
crcProjectId = "Demo"
ontProjectId = ${i2b2ShrineProjectName}
}
breakdownResultOutputTypes {
PATIENT_AGE_COUNT_XML {
description = "Age patient breakdown"
}
PATIENT_RACE_COUNT_XML {
description = "Race patient breakdown"
}
PATIENT_VITALSTATUS_COUNT_XML {
description = "Vital Status patient breakdown"
}
PATIENT_GENDER_COUNT_XML {
description = "Gender patient breakdown"
}
} //end breakdown section
hub {
client {
serverUrl = ${shrineHubBaseUrl}
}
}
queryEntryPoint {
broadcasterServiceEndpoint {
url = ${shrineHubBaseUrl}/shrine/rest/broadcaster/broadcast
}
}
adapter {
crcEndpoint {
url = ${i2b2BaseUrl}/i2b2/services/QueryToolService/
}
adapterMappingsFileName = "AdapterMappings.csv"
crcRunQueryTimeLimit = "30 seconds" // in seconds, use quotes. default 30 seconds
} //end adapter section
keystore {
file = "/opt/shrine/shrine.keystore"
password = "password"
privateKeyAlias = "your_private_key_alias"
keyStoreType = "JKS"
caCertAliases = ["shrine-hub-ca"]
} //end keystore section
steward {
createTopicsMode = Approved //the default is Pending - the most secure - but most sites use Approved
emailDataSteward {
sendAuditEmails = false //false to turn off the whole works of emailing the data steward
//interval = "1 day" //Audit researchers daily
//timeAfterMidnight = "6 hours" //Audit researchers at 6 am. If the interval is less than 1 day then this delay is ignored.
//maxQueryCountBetweenAudits = 30 //If a researcher runs more than this many queries since the last audit audit her
//minTimeBetweenAudits = "30 days" //If a researcher runs at least one query, audit those queries if this much time has passed
//You must provide the email address of the shrine node system admin, to handle bounces and invalid addresses
//from = "shrine-admin@example.com"
//You must provide the email address of the data steward
//to = "shrine-steward@example.com"
//subject = "Audit SHRINE researchers"
//The baseUrl for the data steward to be substituted in to email text. Must be supplied if it is used in the email text.
//stewardBaseUrl = "https://example.com:6443/shrine-api/shrine-steward/"
externalStewardBaseUrl = "https://example.com:6443/shrine-api/shrine-steward/"
//Text to use for the email audit.
//AUDIT_LINES will be replaced by a researcherLine for each researcher to audit.
//STEWARD_BASE_URL will be replaced by the value in stewardBaseUrl if available.
//emailBody = """Please audit the following users at STEWARD_BASE_URL at your earliest convenience: AUDIT_LINES"""
//note that this can be a multiline message
//Text to use per researcher to audit.
//FULLNAME, USERNAME, COUNT and LAST_AUDIT_DATE will be replaced with appropriate text.
//researcherLine = "FULLNAME (USERNAME) has run COUNT queries since LAST_AUDIT_DATE."
}
} //end steward section
} //end shrine
New nodeKey parameter
The nodeKey parameter will be used to identify your node from the Hub, so we advise that it should be a relatively unique identifier along with the network in which you are in, ie. HarvardProdNode or similar. If you have any questions, please contact the network administrator for more information.
Changes to SHRINE databases
In SHRINE 2.0.0, there are a couple of database changes that you will need to perform to accommodate the new tables and structures needed for SHRINE to work properly.
Remove the PRIVILEGED_USER table and associated constraints and sequences from your database
use shrine_query_history; DROP TABLE PRIVILEGED_USER;
Drop the column of actual patient counts from the adapter's COUNT_RESULT table
Shrine no longer needs to store the actual (and mildly sensitive) actual count of patients from the CRC in its COUNT_RESULT table. In mysql remove it from the shrine_query_history database with
use shrine_query_history; ALTER TABLE COUNT_RESULT DROP COLUMN ORIGINAL_COUNT;
Drop the column of actual patient counts from the adapter's BREAKDOWN_RESULT table
Shrine no longer needs to store the actual (and mildly sensitive) actual count of patients from the CRC in its BREAKDOWN_RESULT table. In mysql remove it from the shrine_query_history database with
use shrine_query_history; ALTER TABLE BREAKDOWN_RESULT DROP COLUMN ORIGINAL_VALUE;
Add a status column for queries at the QEP
Add a status column to qepAuditDB's previousQueries table to support updates in query status with :
MySQL:
use qepAuditDB; ALTER TABLE previousQueries ADD COLUMN status VARCHAR(255) NOT NULL DEFAULT 'Before V26';
MS SQL:
use qepAuditDB; ALTER TABLE previousQueries ADD status VARCHAR(MAX) NOT NULL DEFAULT 'Before V26';
ORACLE:
use qepAuditDB; ALTER TABLE "previousQueries" ADD "status" VARCHAR2(256) DEFAULT 'Before V26' NOT NULL;
Added table QUERY_PROBLEM_DIGESTS
MySQL:
use qepAuditDB; create table QUERY_PROBLEM_DIGESTS (NETWORKQUERYID BIGINT NOT NULL, CODEC TEXT NOT NULL, STAMP TEXT NOT NULL, SUMMARY TEXT NOT NULL, DESCRIPTION TEXT NOT NULL, DETAILS TEXT NOT NULL, CHANGEDATE BIGINT NOT NULL); create index queryProblemsNetworkIdIndex on QUERY_PROBLEM_DIGESTS(NETWORKQUERYID);
MS SQL:
use qepAuditDB;
create table "QUERY_PROBLEM_DIGESTS" ("NETWORKQUERYID" BIGINT NOT NULL,"CODEC" VARCHAR(MAX) NOT NULL,"STAMP" VARCHAR(MAX) NOT NULL,"SUMMARY" VARCHAR(MAX) NOT NULL,"DESCRIPTION" VARCHAR(MAX) NOT NULL,"DETAILS" VARCHAR(MAX) NOT NULL,"CHANGEDATE" BIGINT NOT NULL);
create index "queryProblemsNetworkIdIndex" on "QUERY_PROBLEM_DIGESTS" ("NETWORKQUERYID");
ORACLE:
use qepAuditDB;
create table "QUERY_PROBLEM_DIGESTS" ("NETWORKQUERYID" NUMBER(19) NOT NULL,"CODEC" VARCHAR(256) NOT NULL,"STAMP" VARCHAR(256) NOT NULL,"SUMMARY" CLOB NOT NULL,"DESCRIPTION" CLOB NOT NULL,"DETAILS" CLOB NOT NULL,"CHANGEDATE" NUMBER(19) NOT NULL);
create index "queryProblemsNetworkIdIndex" on "QUERY_PROBLEM_DIGESTS" ("NETWORKQUERYID");
Added table RESULTS_OBSERVED
MySQL:
use qepAuditDB; create table RESULTS_OBSERVED (NETWORKQUERYID BIGINT NOT NULL, CHECKSUM BIGINT NOT NULL, OBSERVEDTIME BIGINT NOT NULL); create index resultsObservedQueryIdIndex on RESULTS_OBSERVED(NETWORKQUERYID); create index resultsObservedChecksumIndex on RESULTS_OBSERVED(CHECKSUM);
MS SQL:
use qepAuditDB;
create table "RESULTS_OBSERVED" ("NETWORKQUERYID" BIGINT NOT NULL,"CHECKSUM" BIGINT NOTNULL,"OBSERVEDTIME" BIGINT NOT NULL);
create index "resultsObservedQueryIdIndex" on "RESULTS_OBSERVED" ("NETWORKQUERYID");
create index "resultsObservedChecksumIndex" on "RESULTS_OBSERVED" ("CHECKSUM");
ORACLE:
use qepAuditDB;
create table "RESULTS_OBSERVED" ("NETWORKQUERYID" NUMBER(19) NOT NULL,"CHECKSUM" NUMBER(19) NOT NULL,"OBSERVEDTIME" NUMBER(19) NOT NULL);
create index "resultsObservedQueryIdIndex" on "RESULTS_OBSERVED" ("NETWORKQUERYID");
create index "resultsObservedChecksumIndex" on "RESULTS_OBSERVED" ("CHECKSUM");
Make sure you have setenv.sh defined for Tomcat startup
For SHRINE 2.0.0 in addition to the 2.0.1 ACT ontology, we will need to make sure that Tomcat has enough resources to load the ontology and its larger Adapter Mappings file. To do this, you will need to define a setenv.sh file within the tomcat/bin directory:
#!/bin/bash# Set Tomcat options to prevent hanging thread on shutdown export CATALINA_OPTS=" -XX:MaxPermSize=256m -Dakka.daemonic=on " # Set Tomcat options to prevent resource problems with larger ontology v2.0.1 CATALINA_OPTS="$CATALINA_OPTS -server -Xms1024m -Xmx2048m -Duser.timezone=America/New_York
Start SHRINE
PLEASE NOTE
At this time, please reach out to the network hub administrator so that they can add your individual node to the network with the "nodeKey" that was identified in shrine.conf. Once added to the hub, your node should then start sending and receiving queries. You'll also need to tell the admin your domain parameter, so that the domain will be associated with the nodeKey on the hub.
The only thing left to do at this point is start SHRINE back up. Simply do the following:
$ /opt/shrine/tomcat/bin/startup.sh
Verify SHRINE Upgrade
After starting SHRINE up, verify that the upgrade was properly deployed by checking the SHRINE Dashboard for the version number. The exact address you will need to go to depends on your configuration, but the general format looks like the following:
https://your_shrine_host:6443/shrine-api/shrine-dashboard
This is a sample screenshot of the upgraded 2.0.0 dashboard:
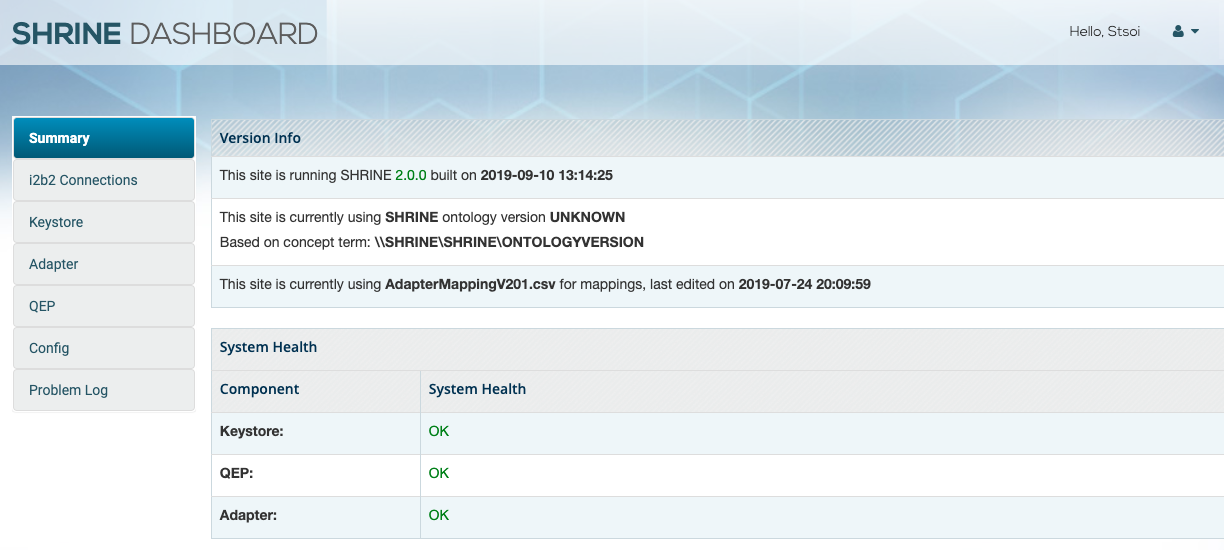
You should check to see if you are able to execute a query and see results come back from your own site as well as others on the network. If you do not see your own site and/or other sites, please submit a JIRA ticket with the issue and notify your network administrator.
Overview
Content Tools