| Table of Contents |
|---|
Reference Docs
| Info |
|---|
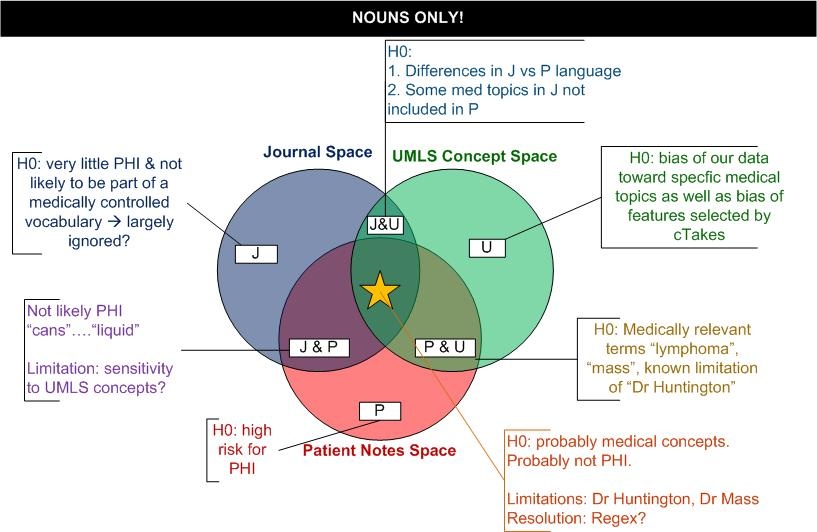
Venn Diagram
Feature Set Construction (Text words-> Lexical Features)
| Office Excel | ||
|---|---|---|
|
| Info |
|---|
3.X is a new vision for the scrubber. As we approached diminishing returns for improving REGEX and whitelists/black lists, we have shifted towards a machine learning methods approach and learning from large bodies of medical information from publications and UMLS dictionaries. |
3.X Diagram In Progress
| Table of Contents |
|---|
Use Case: Tagging Noun Phrases and UMLS concepts
Precondition:
- Training Data: Genia, PenTree Bank, Mayo Source
- Software: cTakes using features POS tagger & UMLS CUID extractor
Steps:
- Block of text is sent to cTakes
- cTakes processing
- start & end position of all POS tags
- part of speech
- Most interested in Nouns because of PHI
- Need Info: are cUIDS associated with WORDS or PHRASES?
Post-condition:
- Input document (either medical note OR publication) will have POS tagged and UMLS CUIDs.
Use Case: Meta-analysis of text
Precondition:
- Tagging Noun Phrases
- Scubber configured (with or without local dictionary/regex mods)
Steps:
- Each "scrubber" implementation procudes Recorder output
- Passthrough Imp
- Regex
- Word lists
- cTakes Impl (OpenNLP)
- Noun Phrases
- UMLS cuids
- Passthrough Imp
- Performance evaluation (ROC)
- Scrubber standalone
- Scrubber word lists limited by detected noun phrases
- Scrubber word lists limited by detected noun phrases and non-UMLS concepts
Post-Condition
...